目的
公司框架为这个。且大多数同学不了解这个怎么玩。为了避免采坑太多,这里先学习总结下。
代码地址以及相关介绍
本代码使用spring+spring mvc+spring data jpa+hibernate+mysql(8.0之后的版本)
git地址:https://github.com/skydh/SpringJpaLearn
为了方便公司的小伙伴们看。
公司内部git地址:http://git.ipo.com/donghang846/spring-jpa-learn.git
单表的3种简单查询模式以及注意点。
1.直接调用接口自带的方法。我们继承的是JpaRepository接口。主要有
count() 获取表多少数据。
findOne() 根据id获取数据。
save() 保存数据。
等。
注意点:
第一点.getone()和findone()作用一样都是根据id获取对象,但是getone是懒加载,没有配置的要报错,还有实体转json的时候也会报错。再看了源代码对接口的解释findOne返回实体,而getOne则是返回实体的引用。总而言之,最好用findOne.
第二点:我们调用save方法时,如果主键不是自增的,我们必须在entity里面增加id,因为jpa会先根据这个id在数据库里面查询数据,如果有数据,那么生成的sql则是更新语句,也就是这个save方法同时承担了更新的职责。
2.在对应的dao接口里面写好方法,调用这个接口即可调用sql获取数据。spring-data-jpa会根据方法的名字来自动生成sql语句,我们只需要按照方法定义的规则即可。规则如我网上找的表。
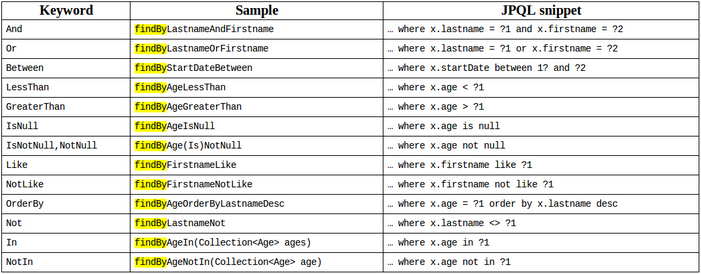
案例如下:
public interface UserDao extends JpaRepository<User, Serializable> {
/**
* 根据name,id 找这个人
* @param name
* @param id
* @return
*/
User findByNameAndId(String name,Integer id);
}
3.当上面2方法都不满足你的需求的时候,或者想自己写sql稳定精确一点的。可以自定义sql。案例如下:
public interface UserDao extends JpaRepository<User, Serializable> {
@Query(value="select * from User where address= :address" ,nativeQuery = true)
List<User> findUserByAddress(@Param("address")String address );
}
这里有几个注意点
1.这里我推荐使用 nativeQuery = true 方式,直接写sql,因为确定了,我们的数据库是mysql,所以我们直接写mysql的sql即可。
2.除了查询语句这种快照读之外,其余所有的语句都要加 @Transactional
@Modifying
例子如下:
@Transactional
@Modifying
@Query(value="update User set address= :address where name= :name")
void updateData(@Param("name")String name,@Param("address")String address);
因为jpa对于非快照操作,要求必须都是事务操作。
多表查询
这边鉴于大多数同学都喜欢mybatis,喜欢写原生sql,这边采用EntityManager这个类来进行多表查询,相对于specification,确实利于优化和调试。
话不多说,上代码:
@Repository
public class UserDao {
@Autowired
private EntityManager entityManager;
public void getUser() {
StringBuilder sb = new StringBuilder();
sb.append("select a.name as name ,b.name as name1 from user a inner join Orders b on a.id=b.user_id");
Query query = entityManager.createNativeQuery(sb.toString());
List<Object> list = query.getResultList();
for (Object user : list) {
System.out.println(user);
}
}
}
如此可以多表查询,且很方便。我们可以在自己拼装sql的时候加逻辑判断。
几个注意点:
1.这个有的表的字段有重复名的我们必须起别名,不然报错。这边最好用有Native关键字的方法,便于我们使用原生sql.
Query query1 = entityManager.createNativeQuery(sb.toString(),UserEntity.class);
第一个返回的都是一个个Object对象,我们要自己拼装成自己需要的vo,但是当sql返回的都是一个表的数据时,我们可以在后面传这个这个类的Class对象。这样不用拼装sql了。但是坑爹的是,我们必须将这个entity的所有字段都要对应上才行。
由于上面要一个个对应字段,太麻烦了,这边写了一个工具类,帮助大家提高效率,和代码工整度。代码就不细说了,有问题联系我修改哈。